6月2日開催された「学術情報の流通を考える-ORCIDとJ-STAGE新バージョン評価版をめぐって-」セミナーに参加しました[1]。
ORCIDの話も面白かったのですが、小倉 辰徳氏によるJ-STAGEの新バージョンの紹介が、いま考え中の課題「本はWeb化するか」の観点から大変参考になりました。セミナーのスライドはこちらです[2]。
J-STAGEは、「見やすく,使いやすいジャーナルサイト構築のため,海外のジャーナルプラットフォームを参考にしつつ,デザインを一新する.」(スライド[2]p5より)として開発中です。機械学会、薬学会より3誌をモデル誌として選択して、1年ほど前からベータ版の運用試験を行っており、2017年度中に全雑誌に適用する予定とのことです。
画面の説明など、詳しくはスライドで紹介されていますのでご参照ください。
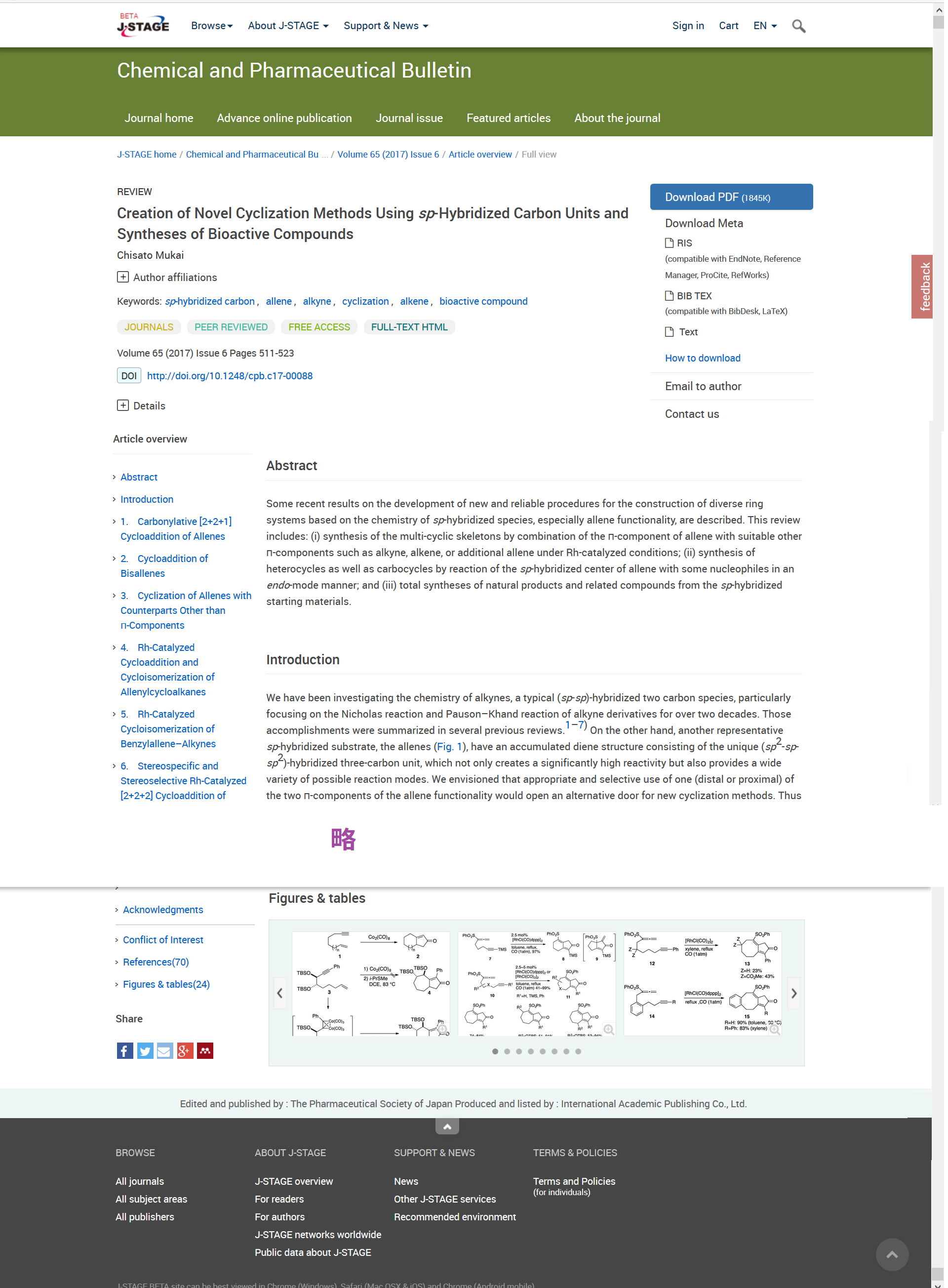
早速、J-STAGEの評価版Webページを見ました。機械学会の「Mechanical Engineering Letters」は全文HTMLではなく、PDFダウンロードです。それに対して薬学会の「Chemical and Pharmaceutical Bulletin」「Biological and Pharmaceutical Bulletin」は全文HTMLを見ることができます。
例えば、Chemical and Pharmaceutical Bulletin[3]は、画面切り替えタブで、ジャーナルのホームページ、発行前の原稿が確定した版(Advance online publication)、各号(Journal issue)、主要論文(Featured articles)、ジャーナルについて(About the journal)に切り替わります。そして各論文の内容はPDFダウンロードに加えて全文HTMLを見ることができます。
ちなみに、Palladium(0)-Catalyzed Benzylic C(sp3)–H Functionalization for the Concise Synthesis of Heterocycles and Its Applications(Volume 65 (2017) Issue 5 Pages 409-425)の全文HTMLのWebページを見てみます[4]。
Webページ全体のデザインは次のようになっています。
このHTMLページは、Window幅を狭くすると2段階のブレークポイントで表示が切り替わります。第1段階ではジャーナル上位のダウンロードメニューが右からジャーナル概要の下に切り替わります。第2段階でArticle overviewのメニューがボタンに縮退します。スマホで見ると次のようになります。

こうしてみますと、まさに現代風のレスポンシブデザインになっています。
そこで、気になるのが、このWebページがどのように作られているかです。ソースファイルを見ますと、Webページは次のような構成になっています。
HTML5で1953行であり、3行目~35行目がhead要素。9個の外部CSSをリンクしています。
36行目~1952行がbodyで、bodyの最後部1378行目~1952行にJavaScriptがあります。かなり直書きされており、全体の行の29%がJavaScriptです。
bodyは次のように分かれています。
・header要素:39~148行
・ジャーナル専用部
・footer要素:1311~1362行目
・フィードバックボタンなど1363~1377行目
header、footerはJ-STAGEシステム全体のメニューなどがあり、ジャーナル専用の部分は149行目~1310行目です。
ジャーナル専用部は次のように分かれています。
・ジャーナル紹介:151~163行目
・画面切り替えのタブ:166~180行目
・パンクズリスト:180~194行目
・記事毎のタイトルと概要・右メニュー:195~306行目
・ジャーナル記事本文:309~1304行目
全体としては記事本文が半分でそれ以外がタイトルやナビゲーションメニュー部となります。
こうしてみますと、Webページは、コンテンツが半分でそれ以外がリンクやナビゲーションのHTMLとCSSとJavaScriptから構成されている、一種のプログラムとデータの集合体と言えます。
Web誕生の頃は、HTMLだけで書いていたのですが、その後HTMLとCSSが分離し、現在のWebページは、HTML+CSS+JavaScriptとなっていますが、このJ-STAGEページはその典型例です。
こうしたWebページはもはや人手でHTMLをコーディングするものではなくなり、CMSに登録したデータからCMSの機能を使って生成しているはずです。そういう意味でCMSに完全依存となっています。
出版物のコンテンツがプログラムと組み合わさってWeb上のアプリケーション化しています。学術情報誌のページとなりますと、こうしたページが何万、何百万個と作られます。そこで、私として一番気になるのは保守コストです。保守は3つに分かれます。
(1)まず、障害対応です。Webページに直書きされているJavaScriptページは一番問題で、ここにバグがあるとWebページそのものを作り直しとなります。
(2)次は改良です。CSSとJavaScriptが膨大になっていますので、これらを改良したとき今までのWebページに問題が起きないかどうか?
(3)次に抜本的な作り直しです。今回のJ-STAGEのユーザーインターフェイスの作り直しは2015年から開始しているとのことですので、既に2年掛かっています。これを2017年度内に全雑誌に適用するということですが、膨大な費用が掛かっているのは間違いありません。
WebのコンテンツをHTMLで作り、CSSでレイアウトし、JavaScriptでインターフェイスを操作する、という流れ。さらにスマホの登場でレスポンシブにするという流れが加わり、Webページのメンテナンスコストがどんどん大きくなっていく傾向にあるように感じます。
ここでもう一度、コンテンツとアプリケーションを分離したEPUB3の良さを見直してみる必要がありそうです。特に、学術論文のようにタイトル数が膨大なものをWebにするとき、プログラムを組み込んでアプリケーション化すると、将来の保守コストが大きな問題になるのは間違いないところです。
[1] XSPAセミナー「学術情報の流通を考える-ORCIDとJ-STAGE新バージョン評価版をめぐって-」のご案内
[2] J-STAGEの評価版について(スライドシェア)
[3] Chemical and Pharmaceutical Bulletin
[4] Palladium(0)-Catalyzed Benzylic C(sp3)–H Functionalization for the Concise Synthesis of Heterocycles and Its Applications(Volume 65 (2017) Issue 5 Pages 409-425)
参考
・ワンソースマルチユースで拓く、ブック型Webページの未来 (ブログ記事2回分を整理したHTMLページ)