CAS-UBは、原稿テキストに対して、簡易マークアップ(CAS記法)で、階層構造や文脈を付与します。
原稿などの編集にはMicrosoft Wordなどを使っている方が多いでしょう。Microsoft Wordは、画面に印刷レイアウト状態で表示しながら編集しますが、こうした方式はWYSIWYG(みたままを出力)といいます。WYSIWYGに慣れているユーザーにとっては、CAS-UBの簡易マークアップ方式には違和感を感じることと思います。
しかし、CAS-UBではどうしても簡易マークアップが必要です。そこで今日は簡易マークアップがなぜ必要かを図版とキャプションの例で説明したいと思います。
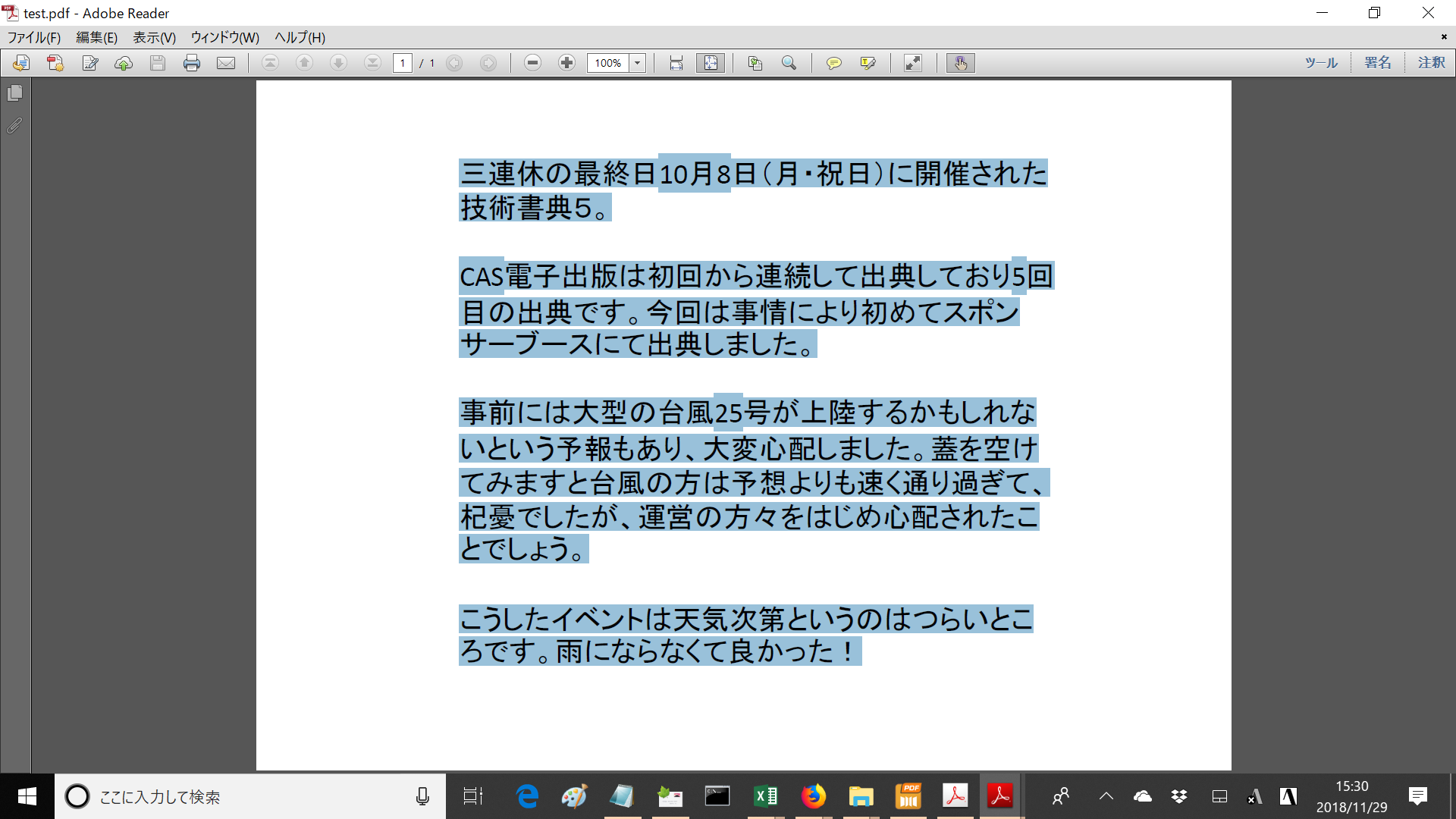
WYSIWYGではレイアウトを視覚的に行います。例えばMicrosoft Wordで次のようなキャプションをつけた図が入った原稿を編集しているとします:

原稿で図の前に一行増えますと、キャプションが次のページに送られて図とキャプションが別のページに分かれてしまいます:

皆さんはこのようなときどうしますか?
おそらく、図とキャプションが別ページになってしまうのを避けるために次のような編集をすることでしょう。
①原稿のテキストを編集して一行短くする
②キャプションの行が同じページになるように図を少し小さくする
③図とキャプションを選択して、改ページ位置の自動修正で「次の段落と分離しない」とする。(この例では図の前で改ページします。)(コメントにより7/2追加)
①、②のような操作はWYSIWYG方式特有です。構造という概念とは無縁です。ちなみに、この原稿を他のツール、例えばInDesignなどで印刷用に仕上げようとします。InDesignの文字の並べ方はMicrosoft Wordとは違うためページ区切りがずれます。Microsoft Wordの上のようなレイアウト操作は無駄だったということになります[1]。③は構造によるページ分割制御ですが、WYSIWYGツールで使う人は少数派のようです。
CAS-UBでは、①紙やPDFのような印刷媒体と、②WebページやEPUBという異なる特性をもつ2種類の媒体を想定して、原稿を再編集しないで両方にワンボタンで出力できます。PDFは自動組版ソフト(AH Formatter[2])によりサーバー上で自動生成します。
原稿に対して、図とキャプションが一体のものであるという構造情報を付与します。そして、この構造を利用してスタイルシートによって図とキャプションが別ページにならないように制御します。つまり構造でレイアウトを制御するのです。
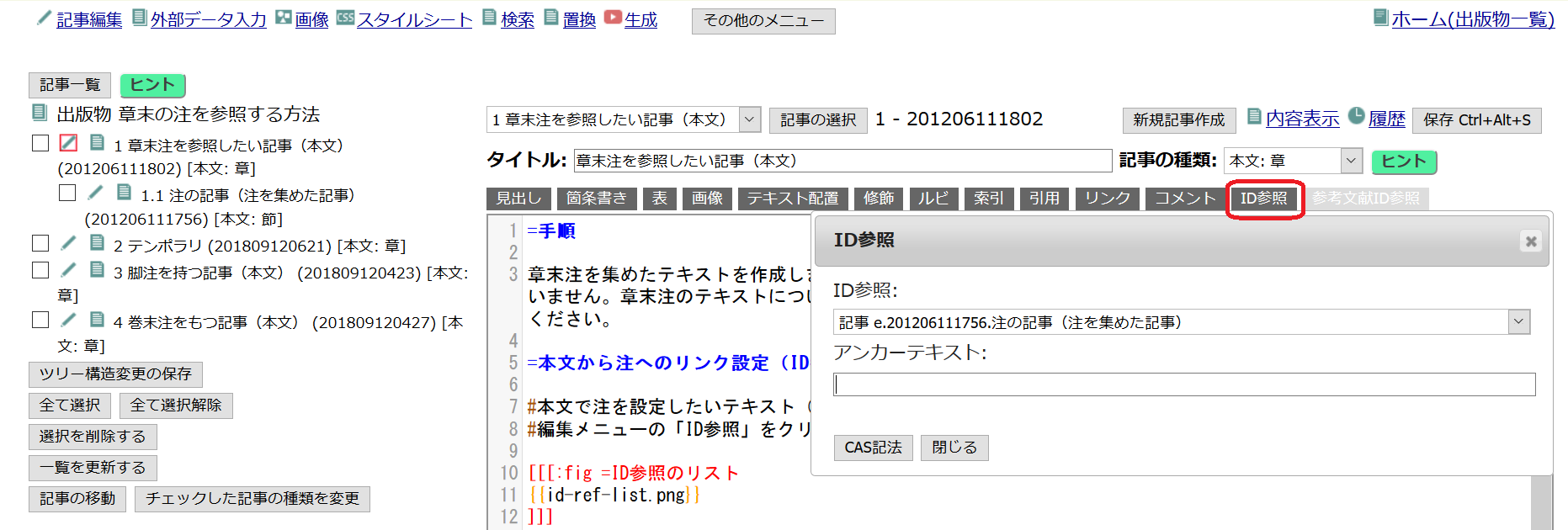
CAS記法では図とキャプションが一体のものであるということを次のように表します。
[[[:fig =透かしの透明度(有無)
{{WaterMarkSetOpacity-example.png}}
]]]
[[[:fig
…
]]]
は図のブロック
=透かしの透明度(有無)
はキャプションです。
次に例を示します。
1. CAS記法を指定しないとき
図の次の行にキャプションを置きます。レイアウトは中央揃え・ゴシックとしました。
次図は上が透かしの透明度を0.2、下が同透明度0.7に設定した結果です。
{{:width=80% WaterMarkSetOpacity-example.png}}
:center 図 透かしの透明度(有無)
PDFを生成しますと次のように泣き分かれてしまいます。

2. CAS記法を指定したとき
次図は上が透かしの透明度を0.2、下が同透明度0.7に設定した結果です。
[[[:fig =透かしの透明度(有無)
{{:width=80% WaterMarkSetOpacity-example.png}}
]]]
PDFを生成しますと次のように、図の前で改ページが入ります。

注意
上の処理の問題点は、図の前で改ページするために大きな空きができてしまうことです。
これを回避するためには、図の前の本文テキストと図の位置関係を自動的に逆転処理するというレイアウト設定もできます。上の例では説明を分かりやすくするため図と本文テキストの入れ替えの設定をしていません。なお、現状では、自動的に図を小さくする処理はできません。
[1] 思い出しましたが、Microsoft Wordは、図の挿入方法によって図を小さくしたときの解像度の扱いが違うので、場合によっては有害です。(参考)Wordに埋め込まれたイメージ画像の解像度はどうなるか?
[2] AH Formatter