4月11日にリリースされたWindows 10のアップデート(バージョン1703)でEdgeのEPUBリーダーが一般に使えるようになったとのことですので、早速、Windows 10をアップデートしてEdgeを使ってみました。
EPUB3のサンプルとしては、先日発売しました『XSL-FOの基礎 第2版』を使いました。こちらで公開していますので、ぜひ、ご一読ください。
「XSL-FO の基礎 XML を組版するためのレイアウト仕様」第2版【新発売】
Webに公開してEPUBをWebページと同じようにリンクで開けます。
図1 EdgeでEPUBをWebと同じように開く
まず、Edgeでは、Windowの幅により2段組と1段組で表示されます。表示Windowの幅が広いと2段組で、表示Windowの幅を狭くすると1段組となります。
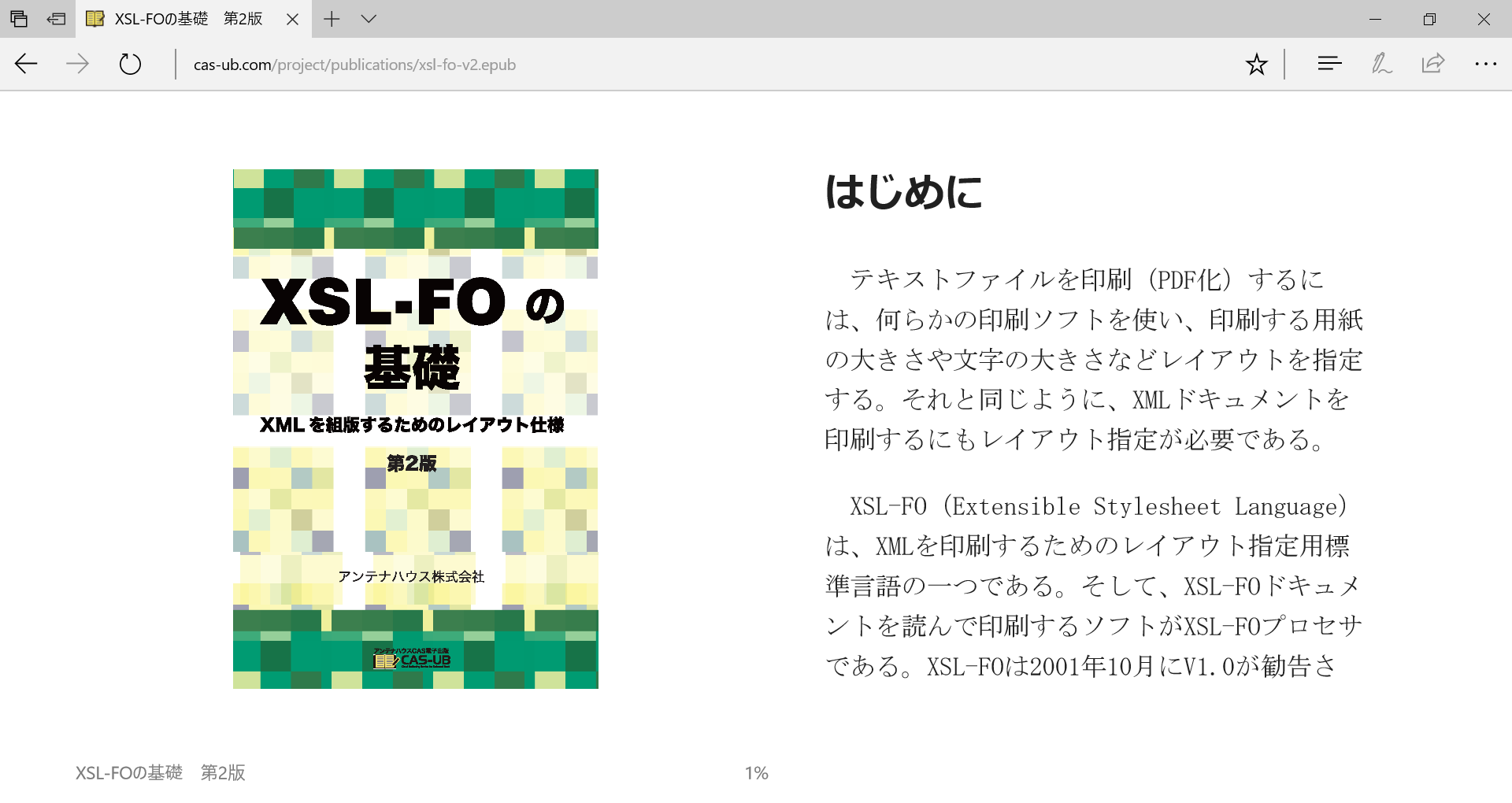
図2 2段組みの表示
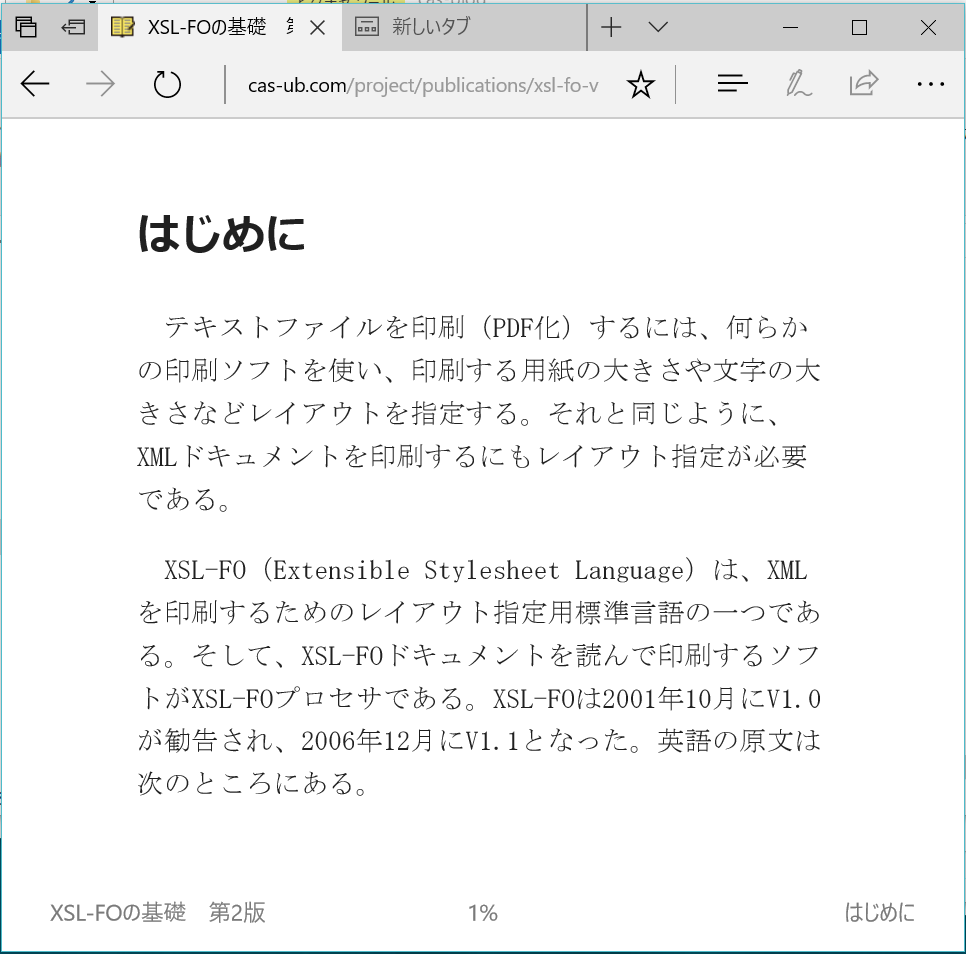
図3 1段組みの表示
ページの下部に柱が出ています。左が本のタイトル、右が章または節の見出しです。これはなかなか良いです。
Windowの上部をタップするとメニューが表示されます。
図4 メニューを表示
メニューは左側に「ナビゲーション目次」「ブックマーク(一覧)」「検索」、右側に「文字など表示設定」「音声読み上げ」「ブックマーク追加」です。次の画面はナビゲーション目次を表示したところです。
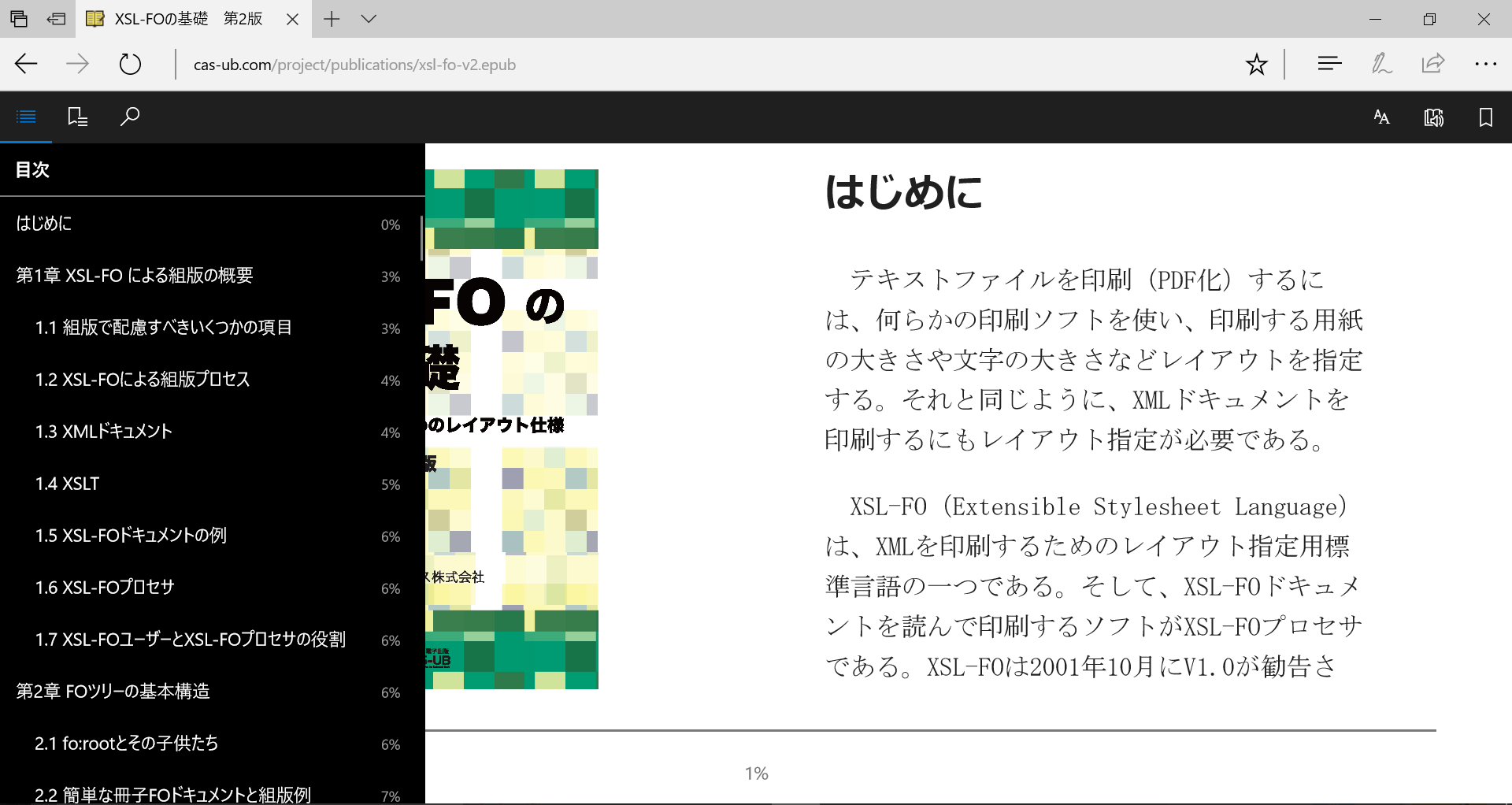
図5 ナビゲーション目次を表示
音声読み上げはなかなか秀逸です。EPUBには音声同期を設定していないのに、読み上げている文節をハイライト表示します。もうメディアオーバレイによる設定は要らなくなります。
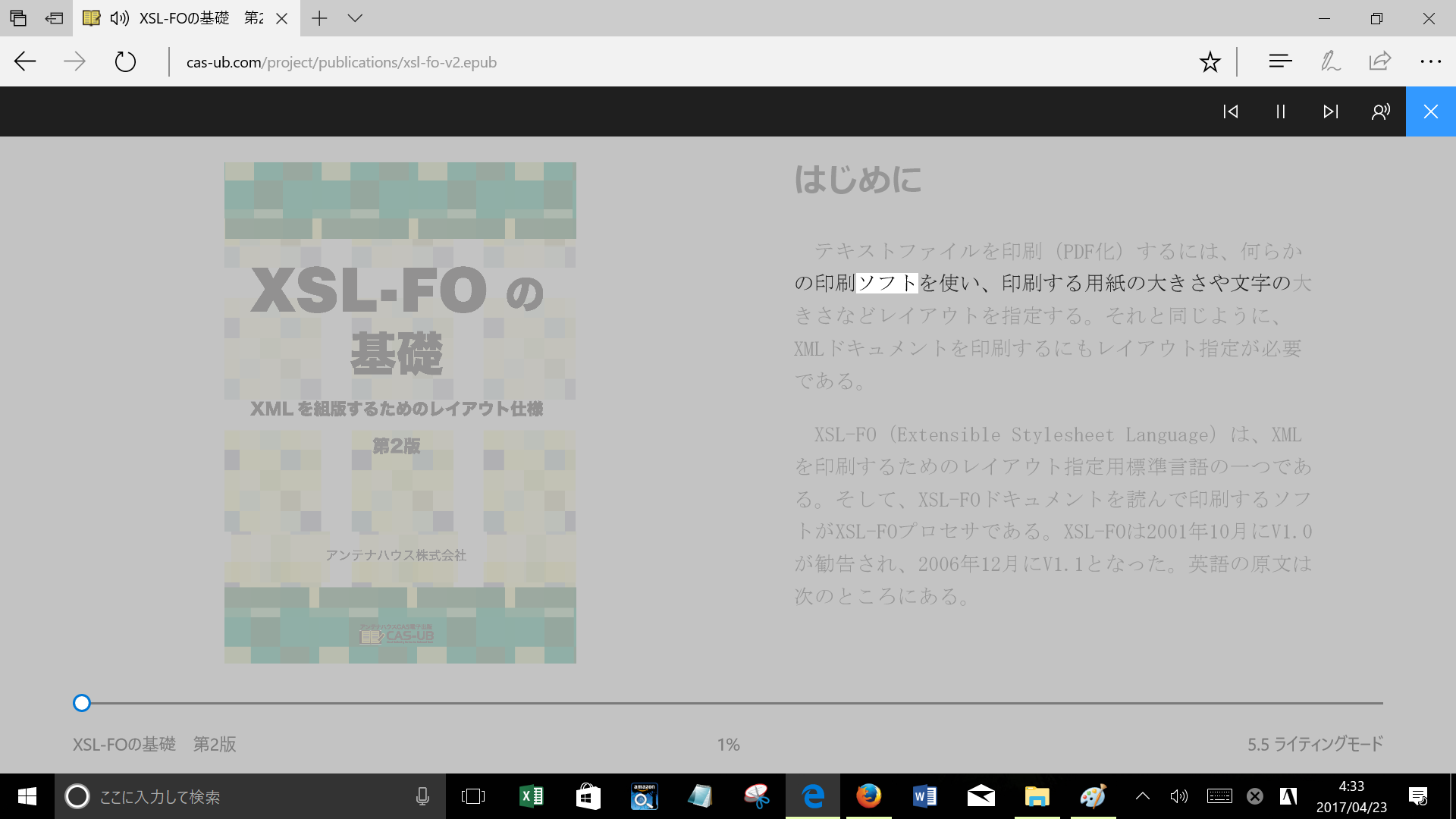
図6 音声読み上げ(ハイライト表示)
このEPUBは、章毎にファイルを分けていますので、新しい章の開始位置で改ページまたは改段します。それは普通です。
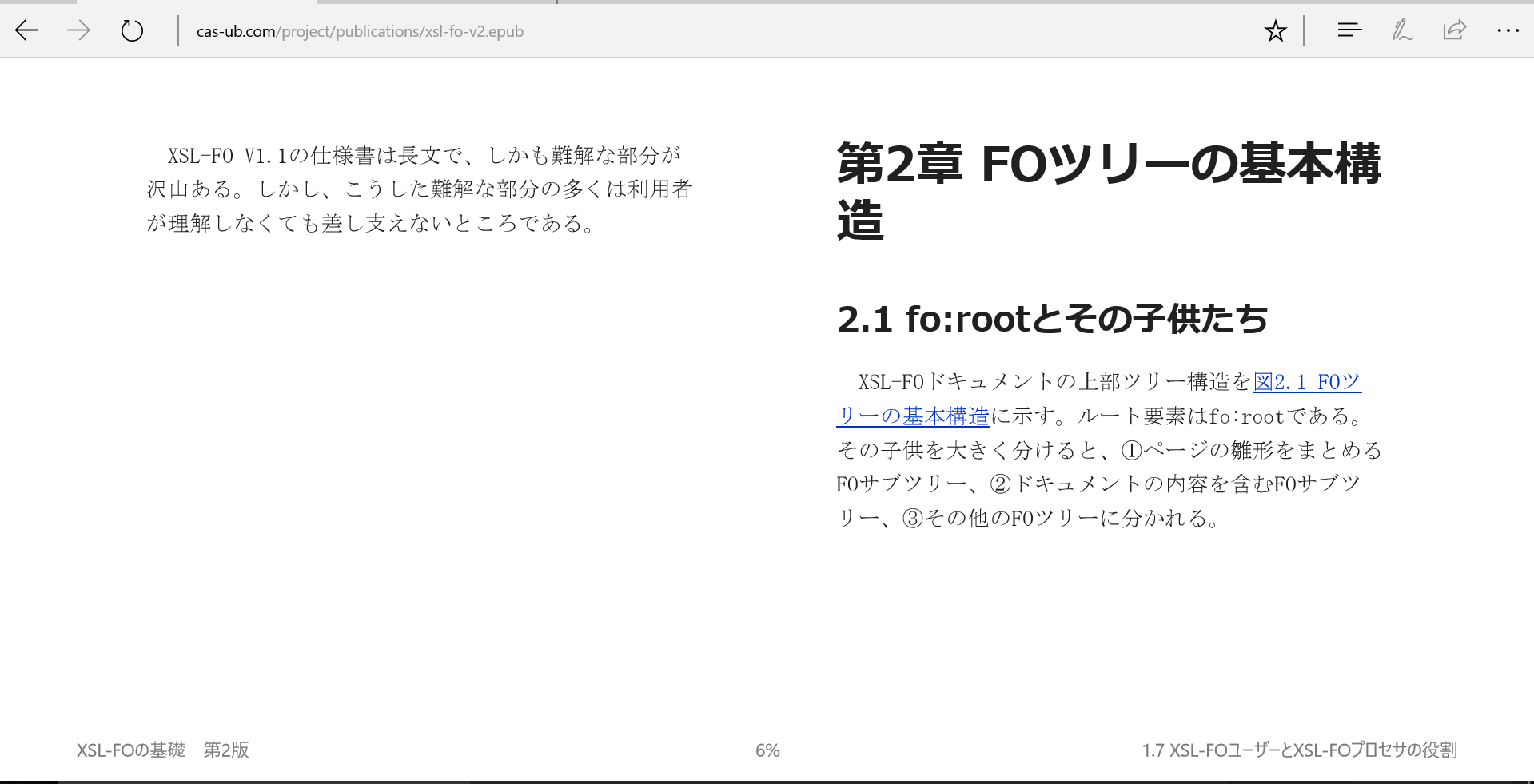
図7 章の開始で改段
さらに、節の見出しと次の本文や見出しが同じ段に入らないとき、泣き別れしないように節の前で改段できます[2]。
図8 節の前で改段
表のテキストだけをポップアップして表示できます。
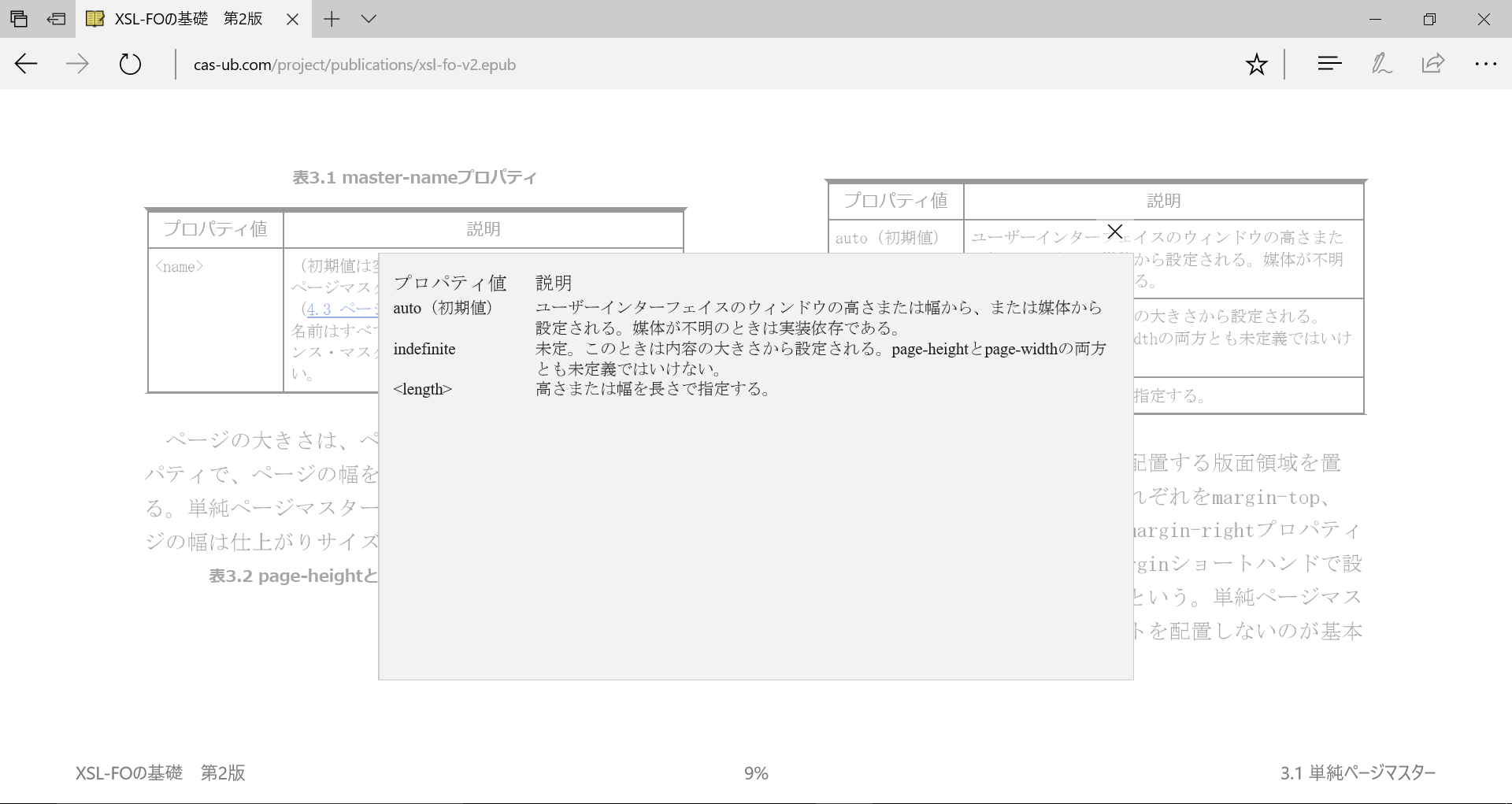
図9 表のテキストをポップアップで表示
画像は幅または高さに合わせて縮小します。ラスターイメージ(このサンプルではPNG)を縮小すると少し汚くなりますが、図だけ拡大表示もできますので問題はないでしょう。なお、図をSVG形式としたEPUB3版も試して見ました(PDF作成用の図をそのまま使ったもの)。SVGも問題なく表示できるようです。いままで、EPUBを作るときはラスターイメージにしていたのですが、これからは公開するEPUBはSVG画像でも良いかもしれません[1]。
気になりましたのは整形済み(pre)のレイアウトです。Edgeではpre要素の前で改ページまたは改段します。これは必要ありません。そしてpreの中では改ページ/改段しません。このためpreの部分が見切れてしまいます。技術系の文書では多くの場合、preの内容はサンプルのコードなのでpreの内容を1段に収める必要はないのです。特に、見切れてしまうのは致命的です。評価用ではなく正式なEPUB3ではpreは使えないということになってしまいます。困りましたね。
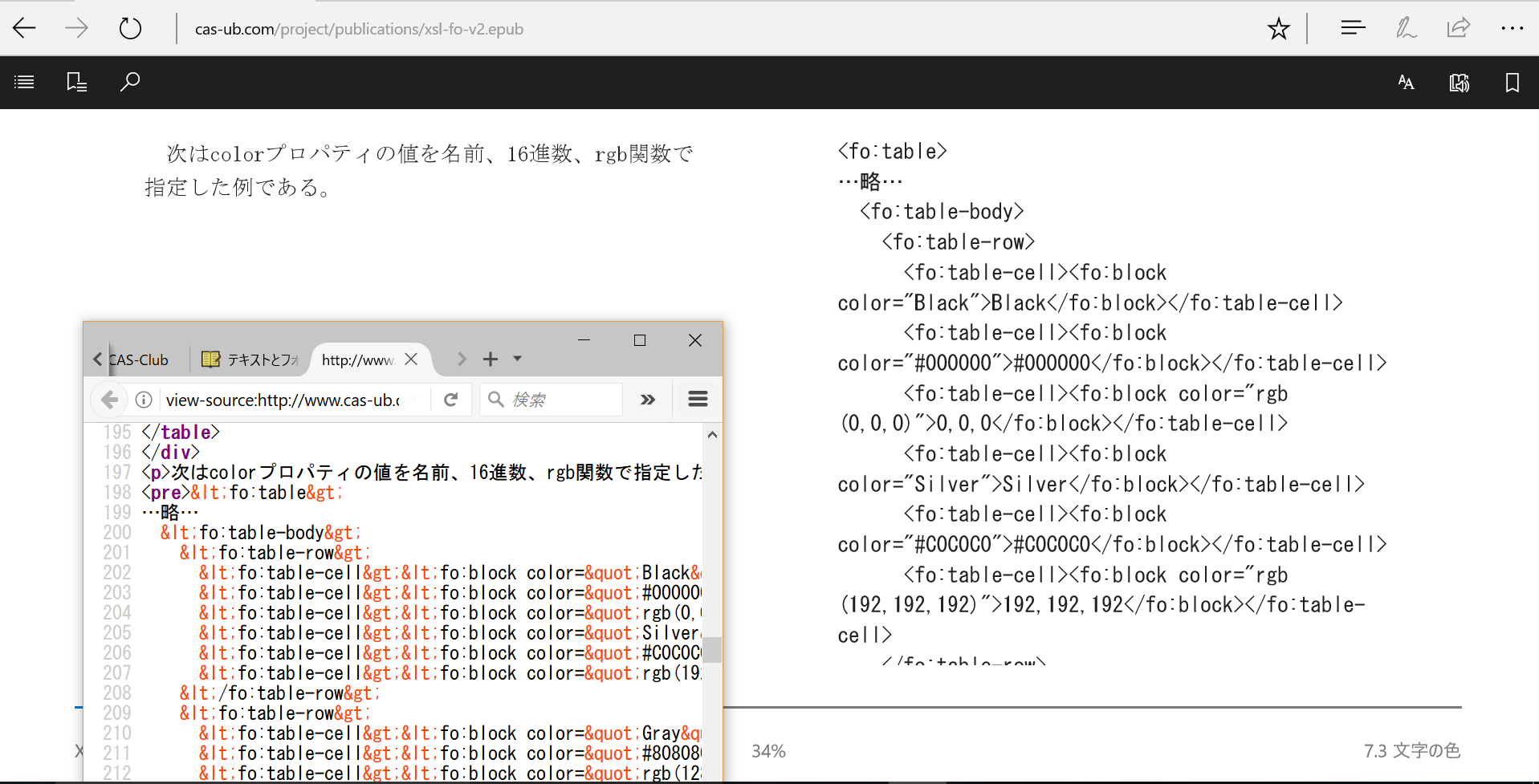
図10 preの前で改段してしまう。preの内容が見切れてしまう
[1] 『XSL-FOの基礎』画像制作のこと。Word経由でインポートした画像は印刷品質の劣化が激しいため、第2版ではできるだけSVG形式に変更した件。
[2] ちなみにiBooksでは次のように見出しと本文が泣き別れしてしまいます(iBooks 4.1.1)。

■関連
『XSL-FOの基礎 第2版』は全文をWebでも公開。CAS-UBでプリントオンデマンド用PDFを作り、Web生成機能でWebページもワンタッチで完成。





