2012年に英数字正立論という考え方を提案してデータをいろいろ検討しました[1]。今年は、時間を作って、もう一度これを見直してまとめてみようと思っています。これは、縦組のときに主にアラビア数字とラテンアルファベットの方向の既定値(何も指定しないときの方向)をどうすべきか、ということですが、関連する問題として、アラビア数字と漢数字の使い分けがあります。
いま、CAS-UBでECMJ流!Eコマースを勝ち抜く原理原則シリーズを編集しているのですが[2]、アラビア数字と漢数字の使い分けの統一は結構やっかいです。
「ひとり」の表記使い分け・新聞方式
そんなことを考えていましたところ、Facebookで「毎日新聞・校閲グループ」の発信[3]の紹介をいただきました[4]。ここで紹介されているのは、「ひとり」のときの「1」と「一」の使い分けです。これは組み合わせとしては次のパターンがあります。
1人
一人
ひとり
1人1人
1人ひとり
一人一人
一人ひとり
ひとりひとり
----------
1人あたり
一人あたり
ひとりあたり
「毎日新聞・校閲グループ」は「他の数字に置き換えにくいものは漢字」と覚えておくといい、とのことです[5]。縦組・横組の区別を何も言及していないので共通と理解して良いのでしょうか(?)ちなみに、『記者ハンドブック第12版』(共同通信社2011年版)の数字の書き方の項(p.569~)は、暗黙に縦組を想定しているようです。成句、慣用句、他の数字に置き換えられない表現に含まれる場合に漢数字として、「一人一人」、「1人当たり」は人数を示すので洋数字という例が出ています。
講談社方式
例えば、『日本語の正しい表記と用語の辞典 第三版』(講談社校閲局編 2015年版)では横組と縦組は分かれています。
・横組は算用数字が基本ですが、編集の意図によっては訓読みは漢字で統一しても良い(p.183)。
但し、横組で算用数字を使うときであっても「副詞的に使われるときや熟した表現では、算用数字をさける。」(横組p.178)とあり、例として一つ一つが掲載されています。
・縦組は、漢数字方式(単位語あり)、漢数字方式(単位語なし)、算用数字方式の3方式併記です。
なお、『新明解国語辞典第六版』では正書法として「一人一人」を記載しています。
新聞方式vs講談社方式比較
とりあえず、毎日新聞・共同通信、講談社で一人と1人の使用例を挙げてみました。講談社版は縦組で算用数字(アラビア数字)を使うときの例外として記載されている例です。
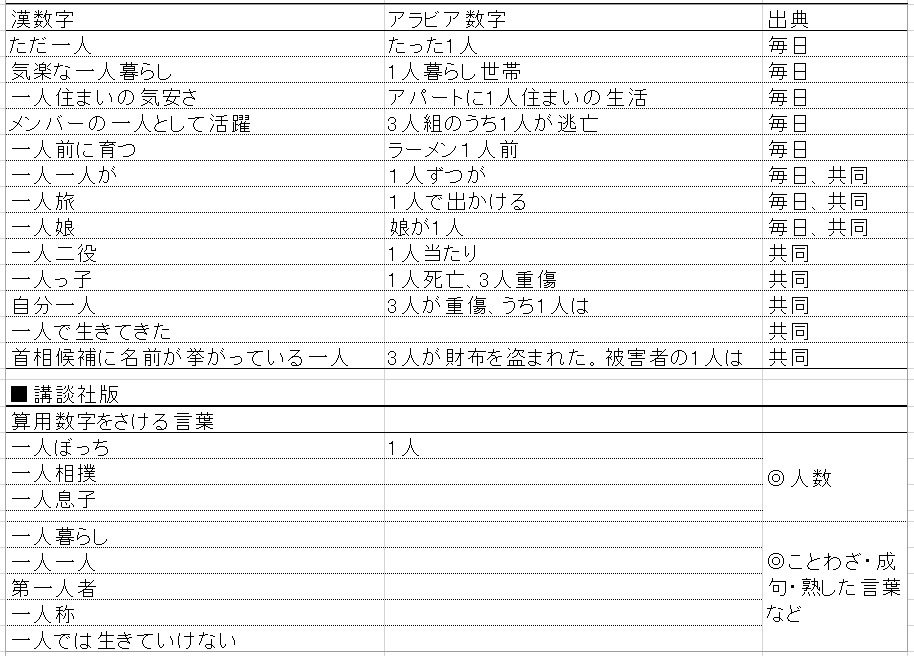
新聞社方式は文脈依存性が強いように思います。しかし、講談社方式は算用数字を使うときでも、成語・慣用句は漢数字となっており比較的明確な基準となっています。
ECMJ!でどうするか
結局、「1人」-「一人」は機械的な統一はできないということなのですが、文章表記を統一するような自動処理(コンピュータ処理)が欲しいところです。で、簡単なのは「ひらがな」にしてしまうことです。結局、ECMJ流!Eコマースを勝ち抜く原理原則シリーズでは、ぜんぶひらがなの「ひとり」に統一することにしました。乱暴過ぎ?
そもそも昔はすべて漢数字だったはず。それが横組の普及でアラビア数字が増えてきて、縦組にもアラビア数字が使われるようになってきたという時代の流れでしょう。そうすると、「一人一人」は漢字というのは盲腸みたいなもので、いずれは、「1人1人」が標準になるのでは? そうすると英数字正立論の出番、といったらこれも革命的過ぎ?
正書法
もう少し調べたところ、『正書法のない日本語』(今野 真二著、岩波書店、2013年4月24日発行)という本がありました。今野さんの主張は次の通りです。
・「正書法」は、言語単位としての語を対象としている。(今野 2013年、p.1)
今野さんは、正書法というときは、正・語があることを前提条件とし、標準的表記は正書法ではないとする。そして日本語には正書法はない、というのですが、その理由は:
・文字種があり、漢字でもカタカナでもよい。
・書き方に選択肢がある。(アシ、足、脚)
・歴史的な考察。かなと漢字という表記原理が異なる文字を常に選択できる。
但し、『正書法のない日本語』はかなと漢字の表記、それも歴史的ないきさつの紹介を主としています。数字についての論考はありません。そもそも表記方法は時と共に変わるものでしょうから、『正書法のない日本語』と言いながら、歴史的な変遷を持ち出すのは本のタイトルと内容の論点がずれているように感じるのですが。
新明解の編集方針には、「正書法」とは、「漢字かな交じり文中における漢字を主体とする表記の、もっとも標準的な書き表わし方として一般に行われるもの」とあります。まあ、確かに、論理的に厳密な意味での正書法はないのかもしれません。新明解的な標準的な書き方を正書法といってはいけないんでしょうか?
[1] 2012年CAS-UBブログ一覧:2012年1月11日~2012年10月19日まで
[2] ECMJ流!Eコマースを勝ち抜く原理原則シリーズ
[3] 校閲発
[4] 仲俣 暁生さんが毎日新聞・校閲グループさんの写真をシェアしました。
[5] 20世紀の新聞は数字は原則漢数字でしたが、大新聞は2000年代(2000年前後が正しいかもしれません)に数字の表記をアラビア数字方式に変更したので新聞社でも「1」と「一」の使い分けに注意が必要になったのでしょう。例えば、使わぬ外字に歴史ありによる。