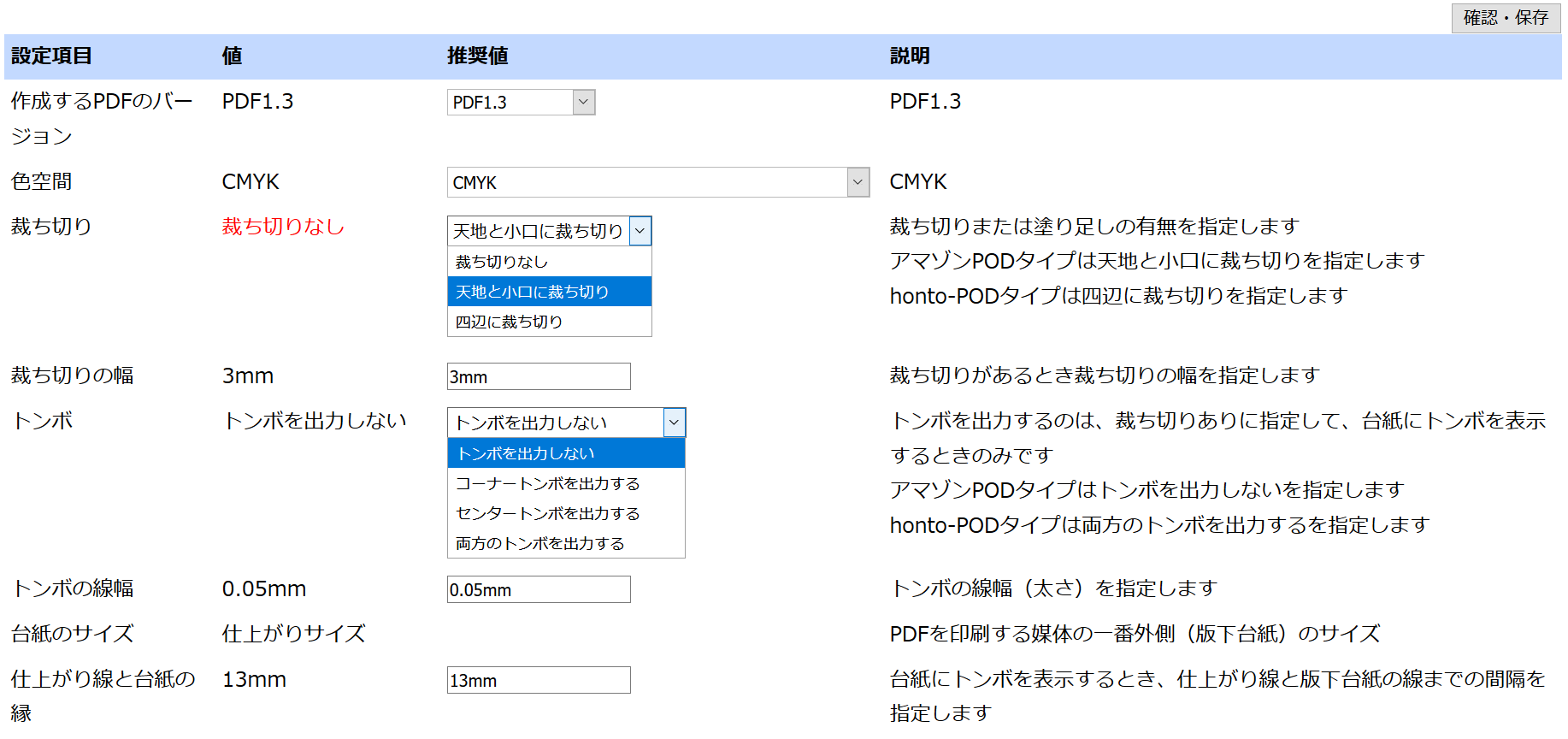
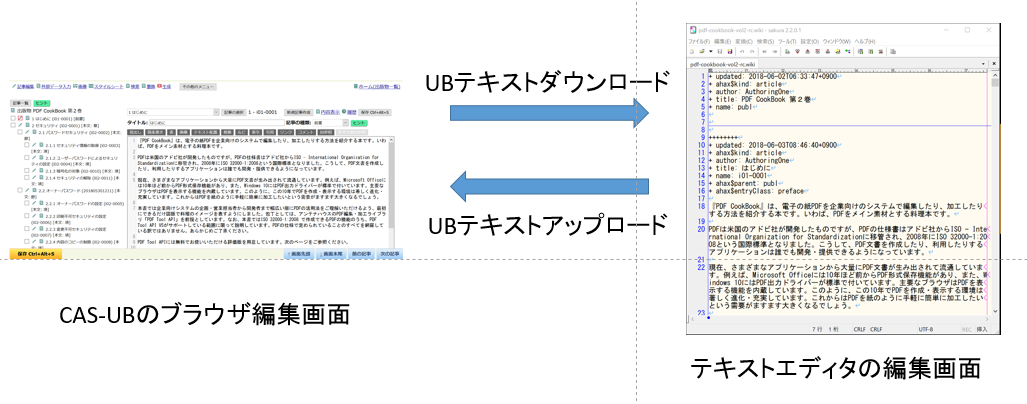
今年発売の『PDF CookBook』シリーズの制作では、UBテキストが大活躍です。2冊とも、アウトライン(章見出し、節見出し、項見出し)の作成はWordで行いました。アウトラインをCAS-UBにインポートして見出しを作った後のテキスト本文編集作業は、USテキスト形式で、ほとんど行なってしまいました。
さらに、Javaのサンプルプログラムを書いた担当者に、UBテキストを渡してプログラム部分を編集(重複している部分を最初に出現した箇所への参照に)してもらいました。UBテキストはwikiを拡張したものですので、プログラマであれば一目で内容が理解できるようです。
テキストエディタは使い易いものがいろいろあります。しかも、無料のものまであります。テキストエディタによる編集は、Webブラウザから操作するよりも、実に素早く便利です。
+ updated: 2018-06-02T06:33:47+0900
+ ahax$kind: article
+ author: AuthoringOne
+ title: PDF CookBook 第2巻
+ name: publ
++++++++
+ updated: 2018-06-03T08:46:40+0900
+ ahax$kind: article
+ author: AuthoringOne
+ title: はじめに
+ name: i01-0001
+ ahax$parent: publ
+ ahax$entryClass: preface
『PDF CookBook』は、電子の紙PDFを企業向けのシステムで編集したり、加工したりする方法を紹介する本です。いわば、PDFをメイン素材とする料理本です。
(省略)
PDF Tool APIには無料でお使いいただける評価版を用意しています。次のページをご参照ください。
[[www.antenna.co.jp/ptl/]]
本書のプログラム例はJava で作成しています。本書で紹介しているプログラム例は次のページよりダウンロードしていただけます。
[[www.antenna.co.jp/ptl/cookbook/source/]]
(省略)
本書はシリーズ2巻目にあたります。第2巻では、PDF Tool APIの機能のうち第1章セキュリティ、第2章透かし、第3章しおりをテーマに取り上げています。シリーズ初巻には巻番号が付いていませんが、本書の本文中では『PDF CookBook』第1巻として参照しています。
++++++++
+ updated: 2018-06-03T08:46:40+0900
+ ahax$kind: article
+ author: AuthoringOne
+ title: セキュリティ
+ name: i02-0001
+ ahax$parent: publ
+ ahax$entryClass: chapter
ISO 32000-1:2008(以下、ISO 32000-1)は権限をもたないユーザーによるPDF文書へのアクセスを防止するための暗号化機能として、共通鍵(パスワード)による暗号化と公開鍵による暗号化の2種類を規定しています。本章の第1節ではパスワードによる暗号化の機能と使い方を説明します。PDF Tool APIは公開鍵による暗号化の機能はありません。
さらに、PDF Tool APIは、ISO 32000-1には規定されていない、独自の閲覧制限機能があります。第3節では独自の閲覧制限の使い方について説明します。
++++++++
+ updated: 2018-06-03T08:46:40+0900
+ ahax$kind: article
+ author: AuthoringOne
+ title: パスワードセキュリティ
+ name: i02-0002
+ ahax$parent: i02-0001
+ ahax$entryClass: section
PDF文書の内容はパスワードによって暗号化することで、権限をもたないユーザーによるアクセスを防止できます。ISO 32000-1の用語ではパスワードによる暗号化機能を標準セキュリティハンドラと呼びます。PDFは上位バージョンほど標準セキュリティハンドラの機能が強化されています。
標準セキュリティハンドラは[[[:index:key=あんごうかのアルゴリズム 暗号化のアルゴリズム]]]として[[[:index RC4]]]と[[[:index AES]]]のどちらかを選択します。当初から使われてきたのはRC4ですが、RC4には、既に脆弱性の点で問題が指摘されています((:footnote [[https://ja.wikipedia.org/wiki/RC4]]))。ASE 128の脆弱性は現時点では問題とされていないようです((:footnote [[ http://www.cryptrec.go.jp/topics/cryptrec_20110912_aes_cryptanalysis.html|128ビットブロック暗号AESの安全性について\\ http://www.cryptrec.go.jp/topics/cryptrec_20110912_aes_cryptanalysis.html]]))。
PDFのバージョンによって暗号化に使うキーの長さに制限があります。[[[:index:key=あんごうかのキーちょう 暗号化のキー長]]]はパスワードの文字数(パスワードの長さ)ではなく、標準セキュリティハンドラが内部的に計算して作成する値です。キーの作成方法はISO 32000-1で規定されています。
[[[:tbl =ISO 32000規定によるPDFバージョンと暗号アルゴリズム・暗号キー長の関係
|=PDFバージョン|=使用できる暗号アルゴリズム|=暗号キー長|
|PDF 1.3|RC4|40|
|PDF 1.4|RC4|40/128|
(省略)
|PDF 1.7アドビ拡張|AES|256|
|PDF 2.0|AES|256|
ISO 32000-1の仕様上は、PDF 1.4以降では暗号化のキー長は40ビット超128ビット以下の範囲で8の倍数単位で設定できます。しかし、PDFアプリケーションの多くは128ビットに固定しています。
]]]
PDF Tool APIでは暗号アルゴリズムの種類と暗号キーの長さを指定できます。
PDF Tool APIでは暗号化するときのキー長は40ビット、128ビット(256ビット)のどちらかを指定できます。一方、暗号を解読するときは8の倍数で可変のキー長の指定を受け付けます。
PDF Tool API V5では、AES 40ビットは設定できません((:footnote AESの仕様では暗号のキー長は128ビット以上とされています。ISO 32000-1でAES 40ビットを規定しているのは誤りの可能性があります。いずれにせよ新しく作成するPDF文書に40ビット暗号は使わないことを推奨します。)
(省略)
PDF Tool APIでは、入力PDF文書のバージョンと指定した暗号アルゴリズムと暗号キーの長さの組みによって、出力されるPDF文書のバージョンは、次表のようになります。
[[[:tbl =PDF Tool APIで出力されるPDF文書のバージョン
|=入力PDF文書のバージョン|=RC4 40|=RC4 128|=AES 128|=AES 256
|PDF 1.3|1.3|1.5|1.6|1.7
(省略)
|PDF 1.7|1.7|1.7|1.7|1.7
]]]
PDF文書には、[[[:index ユーザーパスワード]]]と[[[:index オーナーパスワード]]]のどちらか一方または両方を設定できます。ユーザーパスワードはPDF文書を開くためのパスワードです(詳細は[[##e.i02-0004.ユーザーパスワードによるセキュリティの設定]]を参照)。オーナーパスワードはPDF文書の利用権限を設定するパスワードです(詳細は[[##e.201805301211.オーナーパスワード]]を参照)。
ユーザーパスワードとオーナーパスワードは異なっている必要があります。
*ユーザーパスワードのみ設定されていると、ユーザーパスワードを入力してセキュリティの変更や解除ができます。
*オーナーパスワードのみ設定されていると、オーナーパスワードを入力してセキュリティの変更や解除ができます。
*ユーザーパスワードとオーナーパスワードの両方が設定されていると、(省略)
++++++++
+ updated: 2018-06-03T08:46:40+0900
+ ahax$kind: article
+ author: AuthoringOne
+ title: セキュリティ情報の取得
+ name: i02-0003
+ ahax$parent: i02-0002
+ ahax$entryClass: subsection
{{:width=50% GetCryptInfo-top.png}}
=狙い・効果
PDF文書のパスワードによる[[[:index:key=セキュリティのじょうほうをしゅとく セキュリティの情報を取得]]]します。
=処理の概要
PDF文書のセキュリティ設定は、PDF文書のトレイラーにある暗号辞書に記録されています。暗号辞書からユーザーパスワードの設定状況とオーナーパスワードの権限設定内容を取得して画面に表示します。入力PDF文書にユーザーパスワードが設定されているとき、PDF文書を開くには正しいパスワードの入力が必要です。
=PDF Tool APIの主な機能
*[[[:mindex [[[:nodisp:prim API]]][[[:second setPassword() :暗号化されたPDF文書を読み込む際のパスワードを設定]]]]]]
(省略)
*[[[:mindex [[[:nodisp:prim API]]][[[:second getType() :権限設定タイプ取得]]]]]]
=プログラム例
{{{
package cookbook;
import jp.co.antenna.ptl.*;
public class GetEncryptInfo {
(省略)
}
}
}}}
=プログラムファイル名
GetEncryptInfo.java
=入出力操作の例
{{:width=80% GetEncryptInfo.png}}
次は暗号化キー長256ビットのAESでオーナーパスワード設定したPDF文書の例です。
{{:width=80% GetEncryptInfo1.png}}
次は暗号化キー長256ビットのAESで添付ファイルのみ暗号化したPDF文書の例です。
{{:width=80% GetEncryptInfo-2.png}}