注釈とは、他のコンテンツのある部分に関連つけた内容のことである。PDFやマイクロソフトWordには独自の注釈機能がある。また、電子書籍/EPUBリーダーではKindle、iBooksを初めとしてEPUBのある箇所にしおりをつけたり、マーカーで色をつけたり、コメントを記入する機能がある。
これらの様々な注釈はメディア別に独自の実装が行われており交換可能ではない。注釈を交換可能にするためにはオープンな標準仕様が必要である。現在、Webを中心にさまざまな注釈の標準化が始まろうとしている。
1.注釈を実装するプロジェクト
(1) Annotator(http://annotatorjs.org/)[1]
Annotatorは主にNick StenningとAron Carrollによる、Webに注釈をつけるためのオープンソースのJavaScriptライブラリー開発プロジェクトである。GitHubのコントリビュータをみると、最近はNick Stenningに加えてHypothes.isのRandall LeedsとKristof Csillagがかなりコミットしている[2]。
Annotatorはコアをプラグインにより簡単に拡張できる仕組みになっている。Store(保存用)、Auth(認証用)などのプラグインが用意されている。
注釈データはJSON文書で、指定した対象文書の中で、注釈の位置と内容を示す多数のフィールドから構成している。プラグインを追加するとそのプラグイン用のフィールドが追加される。
現時点で、Annotator v1.2.9(2013/12/3)が最新である。
V2.0の開発が始まっている。
次に述べるHypothes.isをはじめとする様々なプロジェクトで使われている[3]。
(2) Hypothes.is
Hypothes.isは非営利活動法人として、さまざまな団体からの資金をあつめて、Webの注釈サービスを提供する。Hypothes.isは、Open Annotation Collaborationが作成している注釈仕様とAnnotatorプロジェクトを元にしていると主張している。たとえば、Annotatorの初期投稿者であるAron Carrollが製品開発担当として参加している[4]。
2013年4月から”I Annotate”というカンファレンスをサンフランシスコで開催しており、2014年の”I Annotate 2014″は4月3日から5日に開催された[5]。
Hypothes.isは前日に同じ会場で開催されたW3Cの注釈ワークショップのスポンサーになっており、設立間もないにも関わらず注釈サービスの分野で強力な存在になりはじめている。
たとえば、Journal of Electronic Publishingの2014年4月号は、Hypothes.isを採用して学術誌のWeb版に注釈を可能にした(次の図)[6]。
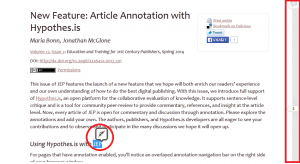
Hypothes.isのブログや公開されたスポンサー(資金源)を見ると、教育分野での注釈にかなりウエイトを置いているように見える。
2.EPUBの注釈
(1) EPUB.js
Fred ChasenによるEPUB表示用JavaScriptである。サンプルの中にHypothes.isと組み合わせてEPUBに注釈を表示するところを示すものがある。”I Annotate 2014″で、Fred Chasenらによるプレゼンが行われている[7]。
(2) Readium
EPUBの仕様を策定しているIDPFはReadiumというEPUBリーダー開発プロジェクトを運営している。ReadiumにはReadiumSDKと、Readium.jsがある。
Readium.jsはChromeの拡張アプリケーションとして配布されているが、注釈機能は用意されていない。
Readium.jsのソースレポジトリにはWeb Annotationのためのレポジトリが用意されているがまだ内容はなにもない[8]。
Readiumは注釈機能の追加を考慮しているが、注釈の標準化がまだということで実装には至っていないように見える。
(3) IDPFのOpen EPUB Annotation (7/29追記)
IDPFは、教育用テキスト向きのEPUBプロファイル仕様の策定を進めている。EDUPUBは、5月28日にすでにドラフトが公開されている。
EDUPUB仕様策定の一環として「Open Annotation in EPUB」仕様のドラフトが作成されている。[13]
W3Cにおける仕様策定作業との関連性が不明であるが、EPUBの注釈仕様は早くできるかもしれない。
3.注釈の標準仕様策定への動き
Open Annotation Collaborationでは「Open Annotation Data Model」というコミュニティ仕様を提案してきた。これは注釈を交換可能な枠組みを作ることを目的としている。この活動は次のW3Cの活動に継承されており、Open Annotation CollaborationのWebサイトは歴史的な目的で保存されている、とされている[9]。
4.W3Cの動き
(1) Open Annotation Community Group
W3Cは、Open Annotation Collaborationの動きを吸収して、Open Annotation Community Groupを開設し、この分野への参入を狙っていた[10]。
(2) 注釈ワークショップ
2014年4月2日にサンフランシスコでW3C初の注釈ワークショップが開催された[11]。″I Anotate 2014″と同じ会場で開催されており、Hypothes.isがスポンサーになっている。
ここでは、既存の注釈システムと注釈の実装、注釈モデルへの一般的な要求、頑健なアンカー、画像などのデータに対する注釈、蓄積とAPI、アクセシビリティと法的な問題というセッションに分けて注釈についての現状と要求のプレゼンテーションがなされた。
注釈の課題についての20のプレゼンテーションがあった。報告書にはプレゼン、ビデオが添付されている。主なものは次の通り。
・注釈の課題は、注釈本体のコンテンツよりも、注釈の本体と対象コンテンツとの関連付けにある(Randall Leeds (Hypothes.is, USA) )。
・マイクロソフト・オフィスオンライン、VisualStudioにおける注釈(Chris Gallello (Microsoft, USA) )
・学術分野における注釈(Anna Gerber (University of Queensland, Australia))
・Logosソフトとサービス。聖書関連の注釈の利用者は注釈にお金を払う。(Sean Boisen (Logos Bible Software, USA))
・出版におけるさまざまな注釈(James Williamson (John Wiley & Sons, USA))
(3) 注釈WG結成への動き
2014年7月14日からデジタル出版活動に注釈のワーキング・グループ(Annotation Working Group)を設立する憲章の検討に入った。WGの憲章は8月19日まで公開レビュー中である。その目的は注釈についてのオープンなアプローチで、ブラウザ、電子書籍リーダー、JavaScriptのライブラリーなどで注釈をつかえるエコシステムを作ることである。開発目標としては次の項目が挙がっている[12]。
(a) 抽象データモデルと語彙の開発:これは、W3CのOpen Annotation Community Groupが開発したOpen Annotation Data Modelからスタートする。
(b) HTMLや埋め込みデータ形式へのシリアライズ
(c) DOMやスクリプトへのインターフェイス
(d) リンクのメカニズム:WebApps Working Groupとの共同で開発する。
9月に最初の電話会議を行い、12月に最初のAnnotation Abstract Data Modelとその語彙(Vocabulary for the Annotation Abstract Data Model)に関する草稿を発行する。
数年で最終成果物として勧告仕様を作成することを目論んでいる。
[1] Annotator
[2] Annotator GitHub
[3] Annotator Showcase
[4] Hypothes.is
[5] “I Annotate 2014”
[6] New Feature: Article Annotation with Hypothes.is
[7] Epub.js: Bringing Open Annotation to Books
[8] web-annotations
[9] Open Annotation Collaboration
[10] Open Annotation Community Group
[11] 注釈ワークショップ報告(Web Annotations Workshop Report)
[12] draft charter for the Annotation Working Group
[13] Open Annotation in EPUB, Draft Specification 28 May 2014
[14] 注釈を利用する形態についての整理